目次
ラグ特徴量作成
時系列解析を行う際に、1列の時系列データを処理して、機械学習モデルへ入力できる形に変換する必要がある。機械学習において最も難しいのが、使うモデルの入力形式に自分のデータセットの形式を揃えることである。
ここでは、サンプル生データの形式を機械学習のモデルへ入力するためのデータへ変換する例を示す。
サンプルデータと目指すデータ形式
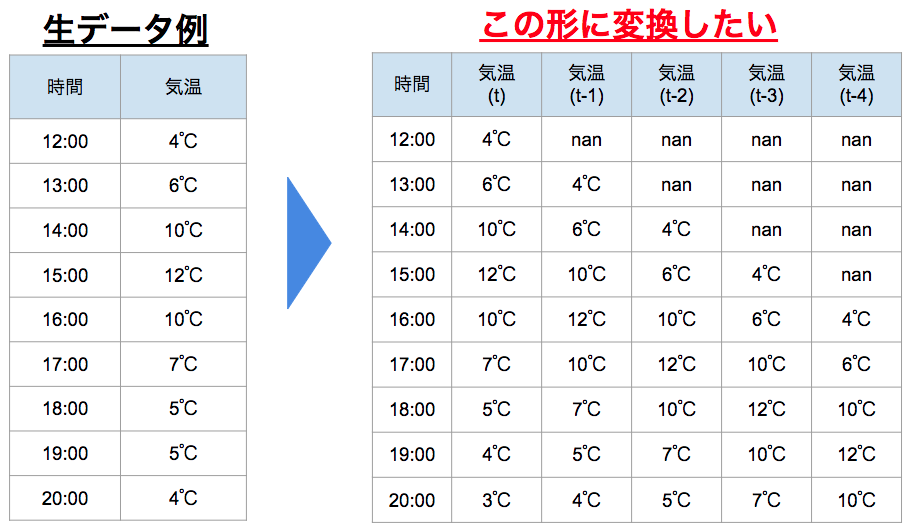
以下のような、毎時間の気温を測定しているデータがあるとする。
狙いとしては、過去(t-1,t-2,…)の気温をもとに、未来(t)の気温を予測するというモデルを作りたいとする。
その場合、ラグ(Lag:遅延)を発生させて、過去のデータを順にならべていきたい。
ちなみに、その時の説明変数及び目的変数は以下のようになる。
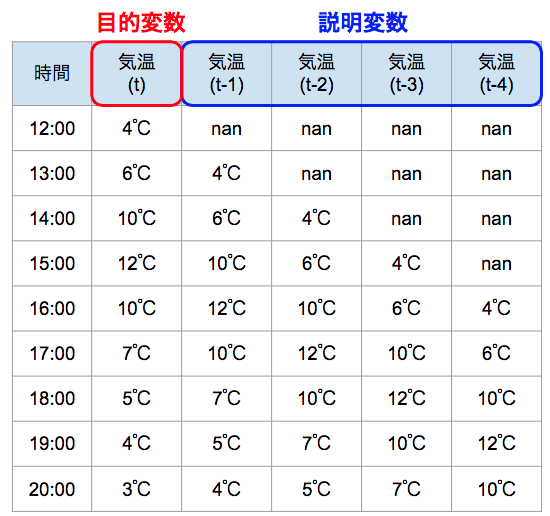
この変換により、説明変数(過去のデータ)を使って目的変数(未来)を予測するという形にすることができる。
コード
変換のためのコードはこちら。
サンプルデータをベタ貼りしておきますので、
中身をメモ帳などにコピーしてsample_data.csvとして保存してください。
ファイルも置いておきます。
# CSVの中身
時間,気温
12:00,4℃
13:00,6℃
14:00,10℃
15:00,12℃
16:00,10℃
17:00,7℃
18:00,5℃
19:00,4℃
20:00,3℃
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("./sample_data.csv", sep=",")
print(df)
# 時間 気温
# 12:00 4℃
# 13:00 6℃
# 14:00 10℃
# 15:00 12℃
# 16:00 10℃
# 17:00 7℃
# 18:00 5℃
# 19:00 4℃
# 20:00 3℃
# ----------ラグ特徴量の作成----------
# 何回ラグを発生させるかを示す。上の例だと5回
number_of_lag = 5
# 特徴量作成のための処理 シフト関数を使い、ずらしてから横に結合
df_lag = pd.DataFrame()
for i in range(1, number_of_lag):
df_lag['x_lag{}'.format(i)] = df['気温'].shift(i)
# ラグなしの元の列と結合
train_df = pd.concat([df_lag, df['気温']], axis=1)
# Nanの処理
train_df.dropna(inplace=True)
# ----ここまでで処理終了-----
print(train_df)
train_df.to_csv('df_lag_future.csv', sep=",", index=False)
# ----必要に応じて以下実施----
# 目的変数と説明変数に分類 及び Dataframe型からndarray型に変換
X = train_df.iloc[:, :number_of_lag-1].values
y = train_df.iloc[:, number_of_lag-1:].values.flatten()
# trainとtestに分類する
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2)あとはお好みのモデルを使ってみてください。
以上でラグ特徴量の作成についての解説を終わります。