KerasでFunctional APIのLSTMユニットを利用する際の入力について解説する。
時系列解析では、データの順番に意味があるためデータの順番には特に注意する必要がある。
目次
Keras LSTM 入力
扱うデータの説明と特徴量作成
扱う生データの例を示す。今回は、過去1時間前と今の気温と湿度情報をもとに、今(もしくは未来)の天気を推定するというモデルを作成するとする。
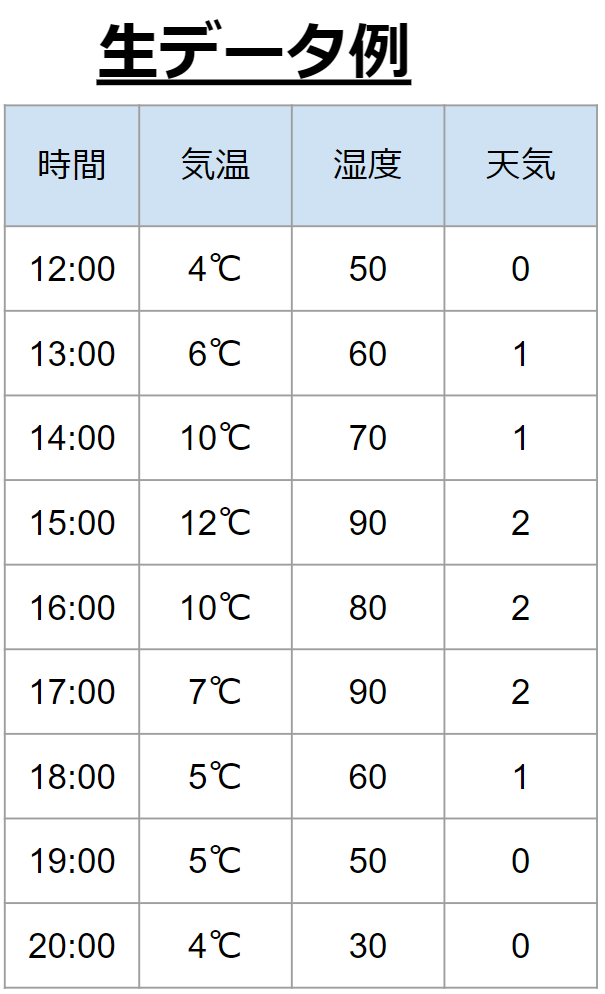
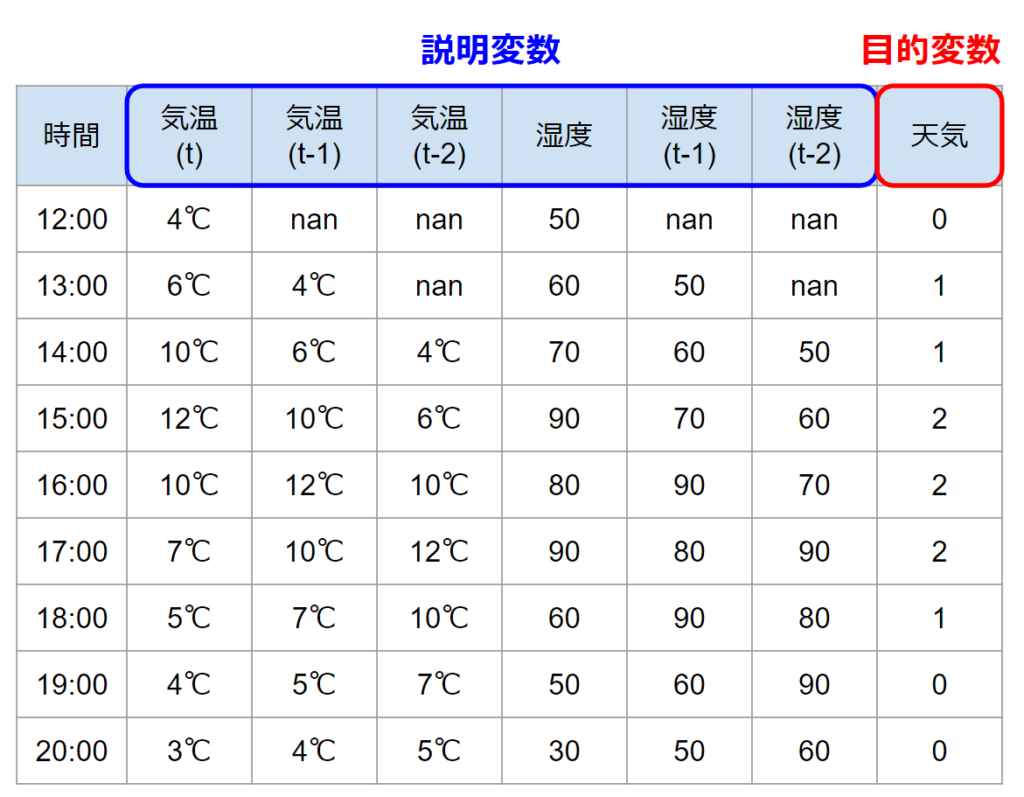
まずはラグ特徴量を作成して、行が時系列の意味を持つデータにする。ラグ特徴量の作成についてはこちらの記事を参考にしてください。
あわせて読みたい


【Python】ラグ特徴量作成(時系列解析のための準備)
【ラグ特徴量作成】 時系列解析を行う際に、1列の時系列データを処理して、機械学習モデルへ入力できる形に変換する必要がある。機械学習において最も難しいのが、使う…
変換を終えて以下のデータにしたとします。timestepsは3(t,t-1,t-2)、featureは2(気温/湿度)のデータです。
Keras LSTM 入力サイズの定義
公式サイト(https://keras.io/api/layers/recurrent_layers/lstm/)によると、LSTMの入力は
inputs: A 3D tensor with shape [batch, timesteps, feature].
そのため、今回の例だと timestepsは3、featureは2なので [batch, 3, 2] となります。
上記の3次元配列になるようにデータを作成する必要があります。
コードは汚いですが一先ず動作確認はできたので困ってる方はこちらを参考にどうぞ。
サンプルデータとして使っている中身とファイルはこちらです。
# sample_data_lstm.csvの中身
気温,湿度,天気
4,50,0
6,60,1
10,70,1
12,90,2
10,80,2
7,90,2
5,60,1
5,50,0
4,30,0import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Input, LSTM, Dense, Concatenate, RNN, GRU
from tensorflow.keras.layers import Dropout, Conv1D, MaxPool1D, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow import keras
# データの読み込み sample_data.csvに上記の生データが入っているとします。
df = pd.read_csv("./sample_data_lstm.csv", sep=",")
# ----------ラグ特徴量の作成----------
# 何回ラグを発生させるかを示す。下の例だと3回
number_of_lag = 3
# 特徴量作成のための処理 シフト関数を使い、ずらしてから横に結合
df_lag_X = pd.DataFrame()
for i in range(1, number_of_lag):
df_lag_X['x_lag{}'.format(i)] = df['気温'].shift(i)
df_lag_Y = pd.DataFrame()
for i in range(1, number_of_lag):
df_lag_Y['y_lag{}'.format(i)] = df['湿度'].shift(i)
# ラグなしの元の列と結合
df_temp = pd.concat([df['気温'], df_lag_X], axis=1)
df_humi = pd.concat([df['湿度'], df_lag_Y], axis=1)
# Nanの処理
df_temp.dropna(inplace=True)
df_humi.dropna(inplace=True)
# rehsapeで一列にする
temp = np.array(df_temp).reshape(-1, number_of_lag)
humi = np.array(df_humi).reshape(-1, number_of_lag)
# [batch, timesteps, feature]の形にする
input_format = []
_format1 = []
for j in range(0, len(temp)):
for i in range(0, number_of_lag):
_tentative = ([temp[j][i], humi[j][i]])
_format1 .append(_tentative)
input_format.append(_format1)
_format1 = []
input_format = np.array(input_format)
print(input_format.shape)
# [9, 3, 2]
# 目的変数のデータを用意
y = pd.concat([df['天気']], axis=1)
y = y[number_of_lag-1:]
# データスプリット
train_X, test_X, train_y, test_y = train_test_split(input_format, y)
early = keras.callbacks.EarlyStopping(monitor='val_loss',
verbose=1,
mode='auto')
cp_callback = keras.callbacks.ModelCheckpoint(
filepath="/training_keras/checkpoint",
verbose=1,
monitor="val_loss",
save_weights_only=True,
save_best_only=True,
period=3)
train_X = np.array(train_X)
train_y = np.array(train_y)
# Model作成
# LSTMモデル作成の時の注意点
# データの順番が新しい時間のデータから古い時間の順になっているため(t, t-1, t-2,..)
# LSTMのオプションにgo_backwards=Trueを付ける必要があります。付けたくない場合は、順番を逆に変更。
inputs1 = Input(shape=(train_X.shape[1], train_X.shape[2]))
lstm = LSTM(16, go_backwards=True)(inputs1)
drop2 = Dropout(0.2)(lstm)
d1 = Dense(10)(drop2)
outputs = Dense(3)(d1)
model = keras.Model(inputs=inputs1, outputs=outputs)
model.compile(optimizer=Adam(learning_rate=0.01),
loss="binary_crossentropy",
metrics=["categorical_accuracy"],)
# 学習
history = model.fit(train_X,
train_y,
validation_split=0.1,
batch_size=5,
epochs=3,
verbose=2,
callbacks=[cp_callback, early])
pred_y = model.predict(test_X)
print(pred_y)ハードコーディングしている箇所については、お持ちのデータセットの名前に合わせてください。