ここでは、BeautifilSoupを使ったスクレイピングの方法について解説をしていきます。
実際に存在するホームページをスクレイピングし、代表的な取得方法と結果を併せた具体例を示しながら分かりやすく進めていきます。
ホームページの構成
まず初めに、ホームページとはどのように構成されているのかについて簡単に説明します。
私たちが普段見ているWebサイトですが、実はマークアップ言語という言語によって作られています。
マークアップ言語とは、文章の論理的な構造や修飾情報に関する指定を文章とあわせてテキストファイルに記述するための言語のことであり、その最も代表的なものがHTMLです。


そのため、スクレイピングを行う際にはHTMLを読み込み、それらの要素や場所を指定することでWebサイトの内容を取得していきます。
具体例を用いた説明
スクレイピングのためのサンプルページが世の中に公開されていますので、サンプルページを例にしながらスクレイピングのためのコードについて説明していきます。
サンプルページはこちらです。
こちらのサンプルページをスクレイピングで読み込み、各要素を取得していきます。
では早速初めて行きましょう
import requests
from bs4 import BeautifulSoup
# 対象となるURLにリクエストを送りHTMLを取得します
res = requests.get('http://quotes.toscrape.com/')
# 戻ってきたHTMLからBeautifulSoupのオブジェクトを作ります
soup = BeautifulSoup(res.text, 'html.parser')
print(soup)これを実行すると、以下のような結果が得られるかと思います。
"""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<title>Quotes to Scrape</title>
<link href="/static/bootstrap.min.css" rel="stylesheet"/>
<link href="/static/main.css" rel="stylesheet"/>
</head>
<body>
<div class="container">
<div class="row header-box">
<div class="col-md-8">
<h1>
<a href="/" style="text-decoration: none">Quotes to Scrape</a>
</h1>
</div>
...(長いため以下省略)
"""実行によって、HTMLを取得することが出来ました。
HTMLだけが欲しい、という場合はこれだけでも使うことができます。
ただ、実際はHTMLの中から必要な要素だけを抜き出すという使い方をします。
次に、タイトルを取得する方法について説明します。
タイトル(title)を取得する
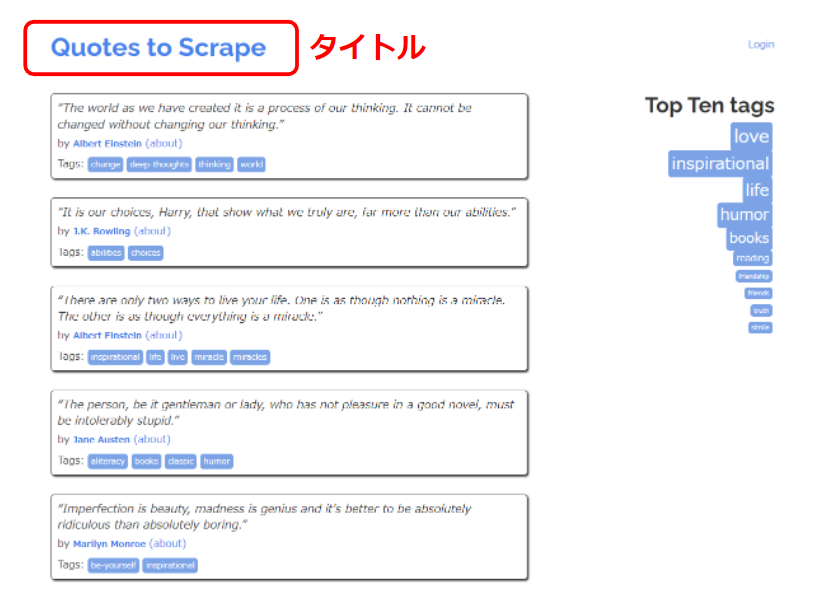
この章では、ホームページのタイトルを取得します。
タイトルとはこの場所です。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<title>Quotes to Scrape</title>
<link href="/static/bootstrap.min.css" rel="stylesheet"/>
<link href="/static/main.css" rel="stylesheet"/>
</head>
サンプルページの中でタイトルはWebサイト一番上の『Quotes to Scrape』、
HTML上では6行目の 『<title>Quotes to Scrape</title>』の場所です。
Pythonを使って取得する方法はこちらです。
# titleタグを取得する
title = soup.find('title').get_text()
print(title)
"""
Quotes to Scrape
"""Aタグを取得
ここでは、Aタグを全て取得する方法について説明します。
まず初めに、基本的な取得方法であるfindを使った方法について解説していきます。
Aタグを全て取得
find_allを使って、任意のタグをすべて取得します。
tag_a = soup.find_all("a")
print(tag_a)
"""
[<a href="/" style="text-decoration: none">Quotes to Scrape</a>, <a href="/login">Login</a>, <a href="/author/Albert-Einstein">(about)</a>, <a class="tag" href="/tag/change/page/1/">change</a>, <a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>, <a class="tag" href="/tag/thinking/page/1/">thinking</a>, <a class="tag" href="/tag/world/page/1/">world</a>, <a href="/author/J-K-Rowling">(about)</a>, <a class="tag" href="/tag/abilities/page/1/">abilities</a>, <a class="tag" href="/tag/choices/page/1/">choices</a>, <a href="/author/Albert-Einstein">(about)</a>, <a class="tag" href="/tag/inspirational/page/1/">inspirational</a>, <a class="tag" href="/tag/life/page/1/">life</a>, <a class="tag" href="/tag/live/page/1/">live</a>, <a class="tag" href="/tag/miracle/page/1/">miracle</a>, <a class="tag" href="/tag/miracles/page/1/">miracles</a>, <a href="/author/Jane-Austen">(about)</a>, <a class="tag" href="/tag/aliteracy/page/1/">aliteracy</a>, <a class="tag" href="/tag/books/page/1/">books</a>, <a class="tag" href="/tag/classic/page/1/">classic</a>, <a class="tag" href="/tag/humor/page/1/">humor</a>, <a href="/author/Marilyn-Monroe">(about)</a>, <a class="tag" href="/tag/be-yourself/page/1/">be-yourself</a>, <a class="tag" href="/tag/inspirational/page/1/">inspirational</a>, <a href="/author/Albert-Einstein">(about)</a>, <a class="tag" href="/tag/adulthood/page/1/">adulthood</a>, <a class="tag" href="/tag/success/page/1/">success</a>, <a class="tag" href="/tag/value/page/1/">value</a>, <a href="/author/Andre-Gide">(about)</a>, <a class="tag" href="/tag/life/page/1/">life</a>, <a class="tag" href="/tag/love/page/1/">love</a>, <a href="/author/Thomas-A-Edison">(about)</a>, <a class="tag" href="/tag/edison/page/1/">edison</a>, <a class="tag" href="/tag/failure/page/1/">failure</a>, <a class="tag" href="/tag/inspirational/page/1/">inspirational</a>, <a class="tag" href="/tag/paraphrased/page/1/">paraphrased</a>, <a href="/author/Eleanor-Roosevelt">(about)</a>, <a class="tag" href="/tag/misattributed-eleanor-roosevelt/page/1/">misattributed-eleanor-roosevelt</a>, <a href="/author/Steve-Martin">(about)</a>, <a class="tag" href="/tag/humor/page/1/">humor</a>, <a class="tag" href="/tag/obvious/page/1/">obvious</a>, <a class="tag" href="/tag/simile/page/1/">simile</a>, <a href="/page/2/">Next <span aria-hidden="true">→</span></a>, <a class="tag" href="/tag/love/" style="font-size: 28px">love</a>, <a class="tag" href="/tag/inspirational/" style="font-size: 26px">inspirational</a>, <a class="tag" href="/tag/life/" style="font-size: 26px">life</a>, <a class="tag" href="/tag/humor/" style="font-size: 24px">humor</a>, <a class="tag" href="/tag/books/" style="font-size: 22px">books</a>, <a class="tag" href="/tag/reading/" style="font-size: 14px">reading</a>, <a class="tag" href="/tag/friendship/" style="font-size: 10px">friendship</a>, <a class="tag" href="/tag/friends/" style="font-size: 8px">friends</a>, <a class="tag" href="/tag/truth/" style="font-size: 8px">truth</a>, <a class="tag" href="/tag/simile/" style="font-size: 6px">simile</a>, <a href="https://www.goodreads.com/quotes">GoodReads.com</a>, <a href="https://scrapinghub.com">Scrapinghub</a>]
"""リンクのみを取得
find_allで取得したURLを使って、リンクのみを取得するような使い方も可能です。
# ページに含まれるリンクを全て取得する
links = [url.get('href') for url in soup.find_all('a')]
print(links)
"""
['/', '/login', '/author/Albert-Einstein', '/tag/change/page/1/', '/tag/deep-thoughts/page/1/', '/tag/thinking/page/1/', '/tag/world/page/1/', '/author/J-K-Rowling', '/tag/abilities/page/1/', '/tag/choices/page/1/', '/author/Albert-Einstein', '/tag/inspirational/page/1/', '/tag/life/page/1/', '/tag/live/page/1/', '/tag/miracle/page/1/', '/tag/miracles/page/1/', '/author/Jane-Austen', '/tag/aliteracy/page/1/', '/tag/books/page/1/', '/tag/classic/page/1/', '/tag/humor/page/1/', '/author/Marilyn-Monroe', '/tag/be-yourself/page/1/', '/tag/inspirational/page/1/', '/author/Albert-Einstein', '/tag/adulthood/page/1/', '/tag/success/page/1/', '/tag/value/page/1/', '/author/Andre-Gide', '/tag/life/page/1/', '/tag/love/page/1/', '/author/Thomas-A-Edison', '/tag/edison/page/1/', '/tag/failure/page/1/', '/tag/inspirational/page/1/', '/tag/paraphrased/page/1/', '/author/Eleanor-Roosevelt', '/tag/misattributed-eleanor-roosevelt/page/1/', '/author/Steve-Martin', '/tag/humor/page/1/', '/tag/obvious/page/1/', '/tag/simile/page/1/', '/page/2/', '/tag/love/', '/tag/inspirational/', '/tag/life/', '/tag/humor/', '/tag/books/', '/tag/reading/', '/tag/friendship/', '/tag/friends/', '/tag/truth/', '/tag/simile/', 'https://www.goodreads.com/quotes', 'https://scrapinghub.com']
"""先頭のAタグの身を取得
先頭のタグのみを取得したい時は、findを使います。
first_tag_a = soup.find("a")
print(first_tag_a)
"""
<a href="/" style="text-decoration: none">Quotes to Scrape</a>
"""任意の順番のAタグを取得
任意の順番のAタグを取得したい場合は、順番を指定することで可能です。
ここでは、リストの2番目にある文字列を取得します。
tag_a = soup.find_all("a")
print(tag_a[1])
"""
<a href="/login">Login</a>
"""取得したタグの属性を取得
取得したタグの属性を取得するには、getを使います。
ここでは、リストの2番目にある上記で示した例の文字列から属性を取得します。
get_attr = tag_a[1].get("href")
print(get_attr)
"""
/login
"""取得したタグの中の文字を取得
取得したタグの文字を取得するには、stringを使います。
ここでは、リストの2番目にある上記で示したtag_a[1]の文字列から文字部分を取得します。
get_str = tag_a[1].string
print(get_str)
"""
Login
"""タグの中の文字列を検索
取得したタグの中に、任意の文字列を含むAタグだけを取得するには、正規表現を使って取得します。
import re
get_live = soup.find_all("a", text=re.compile("live"))
print(get_live)
"""
[<a class="tag" href="/tag/live/page/1/">live</a>]
"""select セレクターを使ったスクレイピング
Beautifil Soupは殆どのCSS4セレクターを使うことが可能です。
ここでは、サンプルとなるURLを例にしながらセレクターによる取得を行っていきます。
サンプルページはこちらです。
まずは、先ほどと同じようにBeautifulSoupのオブジェクトを作っていきます。
import requests
from bs4 import BeautifulSoup
# 対象となるURLにリクエストを送りHTMLを取得します
res = requests.get('http://quotes.toscrape.com/')
# 戻ってきたHTMLからBeautifulSoupのオブジェクトを作ります
soup = BeautifulSoup(res.text, 'html.parser')
クラス名を指定して複数の要素を取得
クラス名を指定するには、 select('.class') を使います。. がポイントです。
ここでは、クラスtagを取得します。
# クラスを指定して取得
tag_class = soup.select('.tag')
print(tag_class)
"""
[<a class="tag" href="/tag/change/page/1/">change</a>, <a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>, <a class="tag" href="/tag/thinking/page/1/">thinking</a>, <a class="tag" href="/tag/world/page/1/">world</a>, <a class="tag" href="/tag/abilities/page/1/">abilities</a>, <a class="tag" href="/tag/choices/page/1/">choices</a>, <a class="tag" href="/tag/inspirational/page/1/">inspirational</a>, <a class="tag" href="/tag/life/page/1/">life</a>, <a class="tag" href="/tag/live/page/1/">live</a>, <a class="tag" href="/tag/miracle/page/1/">miracle</a>, <a class="tag" href="/tag/miracles/page/1/">miracles</a>, <a class="tag" href="/tag/aliteracy/page/1/">aliteracy</a>, <a class="tag" href="/tag/books/page/1/">books</a>, <a class="tag" href="/tag/classic/page/1/">classic</a>, <a class="tag" href="/tag/humor/page/1/">humor</a>, <a class="tag" href="/tag/be-yourself/page/1/">be-yourself</a>, <a class="tag" href="/tag/inspirational/page/1/">inspirational</a>, <a class="tag" href="/tag/adulthood/page/1/">adulthood</a>, <a class="tag" href="/tag/success/page/1/">success</a>, <a class="tag" href="/tag/value/page/1/">value</a>, <a class="tag" href="/tag/life/page/1/">life</a>, <a class="tag" href="/tag/love/page/1/">love</a>, <a class="tag" href="/tag/edison/page/1/">edison</a>, <a class="tag" href="/tag/failure/page/1/">failure</a>, <a class="tag" href="/tag/inspirational/page/1/">inspirational</a>, <a class="tag" href="/tag/paraphrased/page/1/">paraphrased</a>, <a class="tag" href="/tag/misattributed-eleanor-roosevelt/page/1/">misattributed-eleanor-roosevelt</a>, <a class="tag" href="/tag/humor/page/1/">humor</a>, <a class="tag" href="/tag/obvious/page/1/">obvious</a>, <a class="tag" href="/tag/simile/page/1/">simile</a>, <a class="tag" href="/tag/love/" style="font-size: 28px">love</a>, <a class="tag" href="/tag/inspirational/" style="font-size: 26px">inspirational</a>, <a class="tag" href="/tag/life/" style="font-size: 26px">life</a>, <a class="tag" href="/tag/humor/" style="font-size: 24px">humor</a>, <a class="tag" href="/tag/books/" style="font-size: 22px">books</a>, <a class="tag" href="/tag/reading/" style="font-size: 14px">reading</a>, <a class="tag" href="/tag/friendship/" style="font-size: 10px">friendship</a>, <a class="tag" href="/tag/friends/" style="font-size: 8px">friends</a>, <a class="tag" href="/tag/truth/" style="font-size: 8px">truth</a>, <a class="tag" href="/tag/simile/" style="font-size: 6px">simile</a>]
"""タグ名を指定して取得
タグ名を取得するには、select('name') を使います。 タグ名は名前の前に何もつけません。
# タグ名を指定して取得
tag_name = soup.select('p')
print(tag_name)
"""
[<p>
<a href="/login">Login</a>
</p>, <p class="text-muted">
Quotes by: <a href="https://www.goodreads.com/quotes">GoodReads.com</a>
</p>, <p class="copyright">
Made with <span class="sh-red">❤</span> by <a href="https://scrapinghub.com">Scrapinghub</a>
</p>]
"""タグ名取得の際に、個数制限
タグの親子関係を指定して取得するには、limitを使います。
先ほど1つ上で取得した事例の制限を行います。
# 取得する数を1つに制限
only_one = soup.select('p', limit=1)
print(only_one)
"""
[<p>
<a href="/login">Login</a>
</p>]
"""IDを指定して取得
IDを指定して取得するには、select('#id') を使います。# がポイントです。
サンプルページにはIDが含まれていなかったため、使い方だけのご紹介です。
# idを指定して取得
id_number = soup.select('#id')
print(id_number)
"""
[]
"""